关闭容器即信号杀死容器进程
想要停止一个容器的场景很多,比如
- 用户主动delete pod
- node资源不足evict pod(被动删除Pod)
- readness/liveness检测不过,删掉pod
- Docker 停止容器
最后都会用到 Containerd 这个服务。而 Containerd 在停止容器时会向容器的 init 进程发送一个 SIGTERM 信号,
删除容器细节
在 init 进程退出后,容器内的其他进程也都立刻退出了。不过不同的是,init 进程收到的是 SIGTERM 信号,而其他进程收到的是 SIGKILL 信号。
moby项目:daemon/stop.go
1 | func (daemon *Daemon) ContainerStop(name string, timeout *int) error { |
1 | func (daemon *Daemon) kill(c *containerpkg.Container, sig int) error { |
如果上层seconds设置太长会导致优雅等待时间太久么?不会,因为阻塞channel有两个输入,一个是有timeout的ctx, 另一个是容器的退出状态,一旦容器退出(成功or失败)都会写入channel.
在杀死容器时,都是调用该方法,向containerd中的Init进程发送信号。
为什么在停止一个容器时,init 进程收到 SIGTERM 信号,而其他进程却会收到 SIGKILL 信号呢?
init收到SIGTERM我们在前面已经分析过,即containerd对initProcess发送SIGTERM,那容器中其他进程为什么会收到SIGKILL呢?
当容器中 init 进程收到 SIGTERM 信号并且使进程退出,内核对处理进程退出的入口点就是 do_exit() 函数,do_exit() 函数中会释放进程的相关资源,比如内存,文件句 柄,信号量等等。
做完这些工作之后,它会调用一个 exit_notify() 函数,用来通知和这个进程相关的父子进程等。
对于容器来说,还要考虑 Pid Namespace 里的其他进程。调用的是 zap_pid_ns_processes() ,这个函数中,如果是处于退出状态的 init 进程, 它会向 Namespace 中的其他进程都发送一个 SIGKILL 信号。
ns中进程的处理,适合容器场景
1 | void zap_pid_ns_processes(struct pid_namespace *pid_ns) |
整个流程如下图,init process在退出自身的同时,SIGKILL方式通知它的child process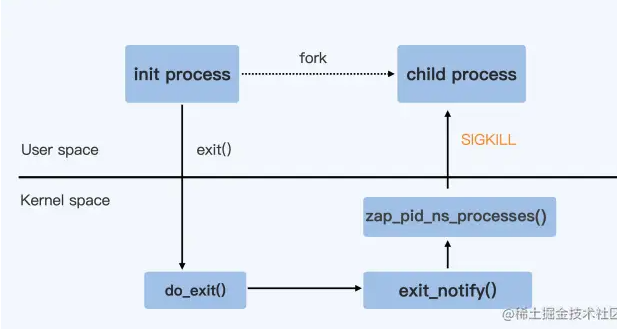
如何让其他child process也收到SIGTERM, 以实现优雅下线呢?
- 容器的应用程序作为
init进程启动, 这涉及Dockerfile的ENTRYPOINT的两种写法,即exec和shell,区别在于:
exec形式的命令会使用PID 1的进程;如果是需要准备工作再启动进程,编写一个entrypoint.shexec 命令的作用时使用新的进程替代原有的进程,并保持 PID 不变, 用exec后面的cmd代替了1
2
3#!/bin/sh
echo "prepare..."
exec java -jar app.jarentrypoint.sh- shell 形式的命令会被执行为 /bin/sh -c ,启动bash进程,不会执行在 PID 1 上,也就不会收到 signal
docker 是如何创建容器的 PID 为 1 的进程?
docker 的 namespace 机制, docker 会在new ns里运行容器。
Linux侧创建新的进程 clone()。
1 | // on host |
多指定 CLONE_NEWPID 参数, 新创建的这个进程将会看到一个全新的进程空间,在这个进程空间里,它的 PID 是 1
为什么我在容器中不能 kill 1 号进程?
想要知道 init 进程为什么收到或者收不到信号,就要去看 sig_task_ignored()的实现

问题和第二个if语句有关,一旦这三个子条件都被满足,那么信号就不会发送给进程, 也就不会处理了。
!(force && sig_kernel_only(sig)):如果是同一个Namespace发出的信号,值为0。所以这个条件总是满足。handler == SIG_DFL:判断信号的handler是否为SIG_DFL(default handler)。SIGKILL不允许捕获,它的handler一直是SIG_DFL,该条件总是满足(提前return 不会发给进程处理)。SIGTERM可捕获,不一定满足(signal会发给进程)t->signal->flags & SIGNAL_UNKILLABLE:进程必须是GINAL_UNKILLABLE的,在每个namespace的init进程建立时就会打上这个标签。(对于init 总是满足)
**可以看出最关键的一点就是 handler == SIG_DFL 。Linux 内核针对每个 Namespace 里的 init 进程,把只有 default handler 的信号都给忽略了。 **
也就是说,如果定义了自定义的handler(SIGKILL不能被自定义), 则信号会发给进程
1 | ### golang init |
在 /proc/[PID]/status文件中,SigCgt 表示 “Signal Catched”,它是进程当前捕获(catch)信号的位掩码。这个位掩码指示了哪些信号已经被该进程设置为自定义的信号处理程序,而不是使用默认的处理程序。
对于init是golang、c、bash程序,应用程序注册的catch信号不
- 对于SIGKILL是无法屏蔽的,所以三种app都会忽略,所以在容器里任何类型的应用都不能杀死init, 这符合逻辑,因为admin通过client拉起容器则由admin通过client杀死容器,岂能由用户通过SIGKILL杀死容器。
- 对于C程序,全部是default handler。则屏蔽所有信号。用C开发的程序偏底层,不允许用户随意发信号。
- 对于bash程序,注册了两个handler( SIGINT(bit2) 和 SIGCHLD(bit17)), 没有注册SIGTERM, 所以会忽略SIGTERM信号。kill也就无法杀死进程。 SIGCHLD信号不能忽略, SIGINT对应ctrl+c的软终端,也不能屏蔽该信号。
- 对于go程序,竟然注册了这么多handler(注册的就要放行), 这里面就放行了SIGTERM,所以kill可以杀死go程序。
允许用户注册的handler,就要保证handler信号的执行,内核不可以屏蔽。不允许注册的handler(默认的信号)则屏蔽信号,保证容器环境的稳定性。
kubectl/docker exec -it container sh
首先要保证容器是持久运行的,然后我们登陆容器打开一个新的shell/bash, 同时也可以看到本次shell执行的是什么命令。
1 | sh-4.4# ps -ef |
1 | # golang init |
当pod中init进程退出后的变化
describe pod 看到的变化
1 | 最初 |
get pod 看到restart count 增加了1
1 | csi-cephfsplugin-provisioner-559dbc494f-pwtjf 5/5 Running 9884 92d |
总结:
- 在杀死容器时,host侧为什么先发送
SIGTERM不行再发SIGKILL呢,因为SIGTERM只能杀死容器里的go app. 对于C/bash app是杀不死的。而SIGKILl时可以杀死所有类型的APP.(在容器里给pid 1手动发SIGKILL是杀不死的) - 那为什么不一次性发
SIGKILL呢?因为太暴力,go程序运行注册SIGTERM handler, 也就是捕获到该信号,在handler中做清理操作后自己退出。SIGKILL太暴力,可能导致app使用的资源泄漏。 - 容器侧
kill -9是杀不死pid 1进程的,因为被内核ignored。对于go app,kill可以杀死 - 在host侧,找到容器里的进程,
SIGTERM是可以杀死的