go kl.cloudResourceSyncManager.Run(wait.NeverStop) kl.initializeModules() go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
下面这三个的启动条件是kubeClient!=nil, 因为涉及到与kube-apiserver的通信,上报节点状态,node not ready是这里设置的 go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop) go kl.fastStatusUpdateOnce() // start syncing lease go kl.nodeLeaseController.Run(wait.NeverStop)
// 调用运行时状态handler,containerRuntime.Status(), 运行时的状态包括两部分, runtime is up(可以创建容器) + runtime network is up(可以为容器配置网络), 写入到runtimeState属性中 go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop) => initializeRuntimeDependentModules 当运行时正常,则初始化运行时所需要的模块(单例模式,值得学习), 这里包括cadvisor, StatsProvider,containerManager,evictionManager,pluginManager(csi and device plugin), 运行时好了,就可以创建pod、containers及volume, device, stats等信息。 kl.initNetworkUtil() // watch channel, 写入端时在syncloop收到删除pod事件 go wait.Until(kl.podKiller, 1*time.Second, wait.NeverStop)
case e := <-plegCh: if e.Type == pleg.ContainerStarted { // 容器启动了,记录最后一个容器的启动 kl.lastContainerStartedTime.Add(e.ID, time.Now()) } if isSyncPodWorthy(e) { // 对于容器是删除,则不需要做pod sync handler.HandlePodSyncs([]*v1.Pod{pod}) } // 如果容器变为了Died,则清理pod中的容器 if e.Type == pleg.ContainerDied { if containerID, ok := e.Data.(string); ok { kl.cleanUpContainersInPod(e.ID, containerID) } }
sync chan 周期任务
1
handler.HandlePodSyncs(podsToSync)
livenessManager
主动杀死的 检测容器是否还活着,liveness
当probe结果是Failure时,HandlePodSyncs
1 2 3 4 5 6
case update := <-kl.livenessManager.Updates(): if update.Result == proberesults.Failure { pod, ok := kl.podManager.GetPodByUID(update.PodUID) ... handler.HandlePodSyncs([]*v1.Pod{pod}) }
housekeepingCh, 管家,清理家
1 2 3 4 5 6 7 8 9 10 11 12 13
case <-housekeepingCh: // 等待资源ready后,才会做cleanup, // If the sources aren't ready or volume manager has not yet synced the states, // skip housekeeping, as we may accidentally delete pods from unready sources. if !kl.sourcesReady.AllReady() { ... } else { klog.V(4).Infof("SyncLoop (housekeeping)") if err := handler.HandlePodCleanups(); err != nil { klog.Errorf("Failed cleaning pods: %v", err) } }
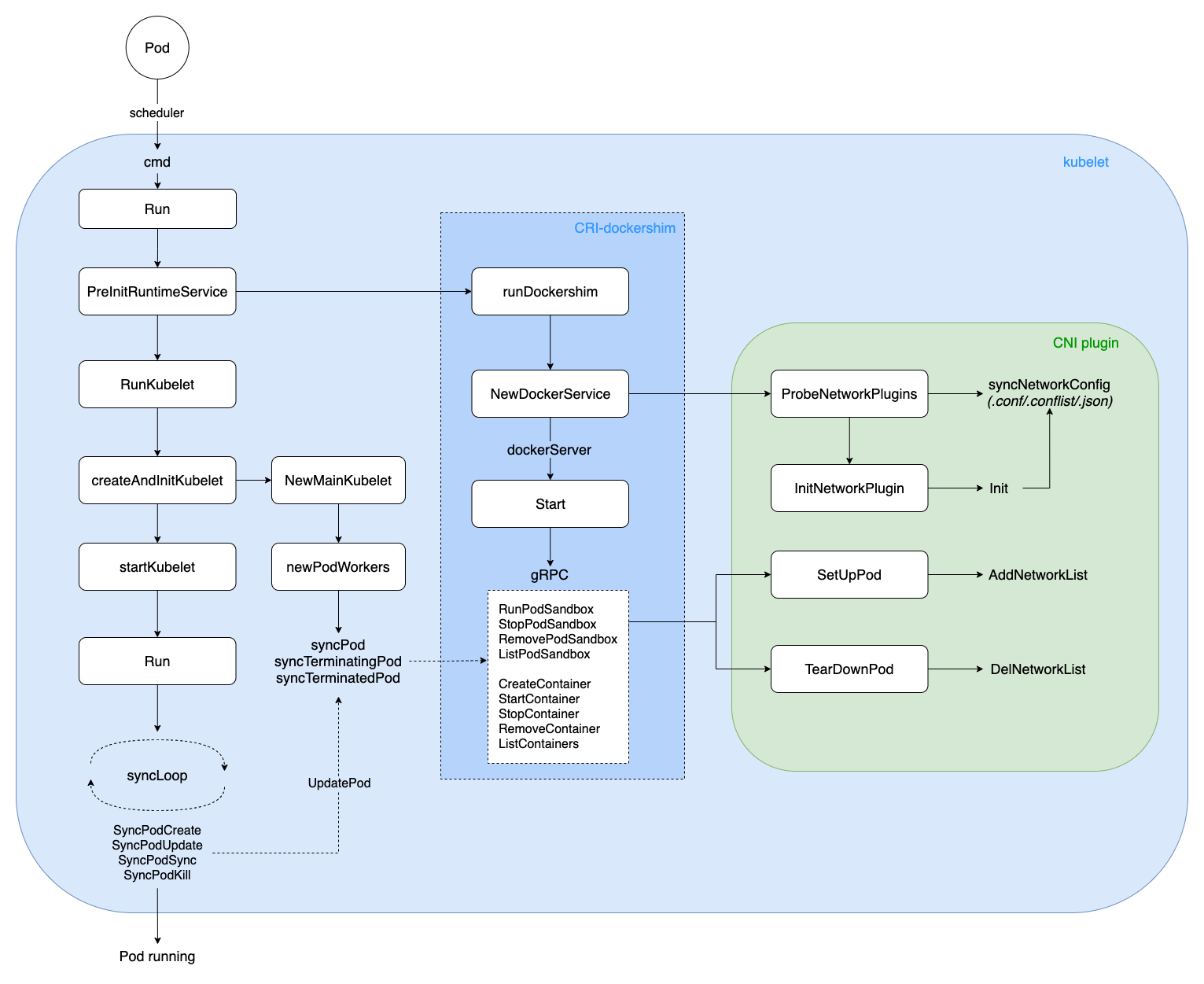
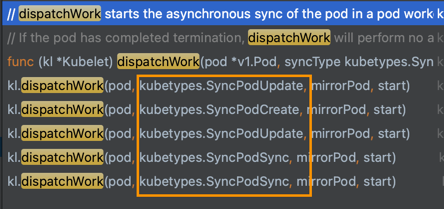
对 pod 进行增删改操作, 其实最后都会跳到 dispatchWork 方法上. 该方法里主要定义了类型 kubetypes.SyncPodType, 然后调用 podWrokers.UpdatePod() 异步操作 pod.
// Step 5: Setup networking for the sandbox. All pod networking is setup by a CNI plugin discovered at startup time. This plugin assigns the pod ip, sets up routes inside the sandbox, creates interfaces etc.
func(kl *Kubelet) HandlePodRemoves(pods []*v1.Pod) { start := kl.clock.Now() for _, pod := range pods { kl.podManager.DeletePod(pod) if kubetypes.IsMirrorPod(pod) { kl.handleMirrorPod(pod, start) continue } // Deletion is allowed to fail because the periodic cleanup routine // will trigger deletion again. if err := kl.deletePod(pod); err != nil { klog.V(2).Infof("Failed to delete pod %q, err: %v", format.Pod(pod), err) } kl.probeManager.RemovePod(pod) } }
 )
)